WebLI-100B:Google DeepMind推出1000億視覺語言數(shù)據(jù)集,助力多模態(tài)AI發(fā)展
隨著人工智能技術(shù)的快速發(fā)展,多模態(tài)模型(Multimodal Models)逐漸成為研究和應(yīng)用的熱點。Google DeepMind近期推出了一個名為WebLI-100B的超大規(guī)模視覺語言數(shù)據(jù)集,包含1000億圖像-文本對,為視覺語言模型(VLMs)的預(yù)訓(xùn)練提供了豐富的資源。本文將詳細(xì)介紹WebLI-100B的核心特點、技術(shù)原理、應(yīng)用場景及其對AI研究的深遠(yuǎn)影響。
WebLI-100B的核心特點
-
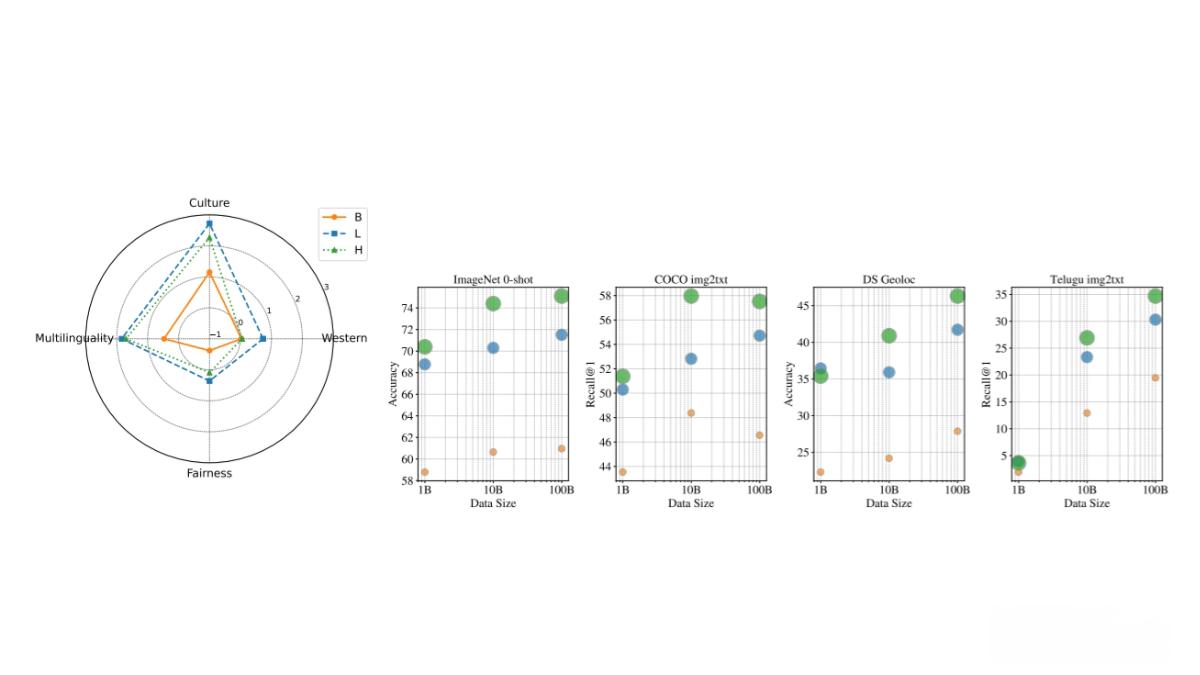
超大規(guī)模數(shù)據(jù)集 WebLI-100B是目前規(guī)模最大的視覺語言數(shù)據(jù)集之一,包含1000億圖像-文本對,是之前最大數(shù)據(jù)集的十倍。這一規(guī)模的提升顯著增強(qiáng)了模型對長尾概念、文化多樣性和多語言內(nèi)容的理解能力。
-
文化多樣性和多語言支持 WebLI-100B的數(shù)據(jù)來源于互聯(lián)網(wǎng),包含來自不同文化背景的圖像和文本。通過基本數(shù)據(jù)過濾(如移除有害圖像和個人身份信息),數(shù)據(jù)集保留了盡可能多的語言和文化多樣性,為訓(xùn)練更具包容性的多模態(tài)模型提供了重要資源。
-
技術(shù)領(lǐng)先 WebLI-100B采用先進(jìn)的數(shù)據(jù)處理技術(shù),包括使用多語言MT5分詞器對文本進(jìn)行分詞處理,并將圖像調(diào)整為224×224像素的分辨率,以適應(yīng)模型的輸入要求。
WebLI-100B的技術(shù)原理
-
數(shù)據(jù)收集
-
來源:WebLI-100B的數(shù)據(jù)主要來源于互聯(lián)網(wǎng),通過大規(guī)模網(wǎng)絡(luò)爬取收集圖像及其對應(yīng)的文本描述(如圖像的alt文本或頁面標(biāo)題)。
-
規(guī)模:數(shù)據(jù)集包含1000億個圖像-文本對,是迄今為止最大的視覺語言數(shù)據(jù)集之一。
-
-
數(shù)據(jù)過濾
-
基本過濾:僅移除有害圖像和個人身份信息(PII),以保留語言和文化多樣性。
-
質(zhì)量過濾(可選):研究中探討了使用CLIP等模型進(jìn)行數(shù)據(jù)過濾,但這種過濾可能會減少某些文化背景的代表性。
-
-
數(shù)據(jù)處理
-
文本處理:使用多語言MT5分詞器對文本進(jìn)行分詞處理,確保多樣性和一致性。
-
圖像處理:將圖像調(diào)整為224×224像素的分辨率,適應(yīng)模型輸入要求。
-
WebLI-100B的應(yīng)用場景
-
人工智能研究者 WebLI-100B為視覺語言模型的預(yù)訓(xùn)練提供了豐富的數(shù)據(jù)資源,幫助研究者探索新算法,提升模型性能。
-
工程師 工程師可以利用WebLI-100B開發(fā)多語言和跨文化的應(yīng)用,如圖像描述生成、視覺問答和內(nèi)容推薦系統(tǒng)。
-
內(nèi)容創(chuàng)作者 數(shù)據(jù)集支持生成多語言的圖像描述和標(biāo)簽,幫助內(nèi)容創(chuàng)作者提升內(nèi)容的本地化和多樣性。
-
跨文化研究者 WebLI-100B為研究不同文化背景下的圖像和文本提供了重要資源,支持文化差異分析。
-
教育工作者和學(xué)生 作為教學(xué)和研究資源,WebLI-100B可以幫助教育工作者和學(xué)生學(xué)習(xí)多模態(tài)數(shù)據(jù)處理和分析。
WebLI-100B的項目地址
-
arXiv技術(shù)論文:https://arxiv.org/pdf/2502.07617
結(jié)語
WebLI-100B的推出標(biāo)志著視覺語言模型研究進(jìn)入了一個新的階段。其超大規(guī)模、文化多樣性和技術(shù)領(lǐng)先性為多模態(tài)AI的發(fā)展提供了重要支持。無論是研究者、工程師還是內(nèi)容創(chuàng)作者,都可以從中受益,推動AI技術(shù)的進(jìn)一步突破。