SepLLM:基于分隔符壓縮加速大語言模型的高效框架
在人工智能領(lǐng)域,大語言模型(LLM)的應(yīng)用越來越廣泛,但隨之而來的是計(jì)算資源的消耗和推理速度的瓶頸。SepLLM,由香港大學(xué)、華為諾亞方舟實(shí)驗(yàn)室等機(jī)構(gòu)聯(lián)合提出,為解決這一問題提供了全新的思路。SepLLM通過創(chuàng)新的分隔符壓縮技術(shù),顯著提升了模型的推理效率和內(nèi)存使用效率,成為大語言模型優(yōu)化領(lǐng)域的又一重要突破。
SepLLM是什么?
SepLLM(基于分隔符壓縮加速大語言模型的高效框架)是一種旨在加速大語言模型推理和訓(xùn)練的框架。它通過壓縮段落信息并消除冗余標(biāo)記,大幅提高了模型的計(jì)算效率和推理速度。SepLLM的核心創(chuàng)新在于利用分隔符(如標(biāo)點(diǎn)符號(hào))對(duì)注意力機(jī)制的貢獻(xiàn),將段落信息壓縮到這些標(biāo)記中,從而減少計(jì)算負(fù)擔(dān)。
SepLLM在處理長(zhǎng)序列(如400萬個(gè)標(biāo)記)時(shí)表現(xiàn)出色,同時(shí)保持了低困惑度和高效率。此外,它支持多節(jié)點(diǎn)分布式訓(xùn)練,并集成了多種加速操作,如fused rope和fused layer norm,進(jìn)一步提升了訓(xùn)練效率。‘
SepLLM的主要功能
1. 長(zhǎng)文本處理能力
SepLLM能夠高效處理超過400萬個(gè)標(biāo)記的長(zhǎng)序列,適用于文檔摘要、長(zhǎng)對(duì)話等需要維持上下文連貫性的任務(wù)。這一功能使得SepLLM在處理大規(guī)模文本數(shù)據(jù)時(shí)表現(xiàn)出色,能夠滿足各種復(fù)雜場(chǎng)景的需求。
2. 推理與內(nèi)存效率提升
在GSM8K-CoT基準(zhǔn)測(cè)試中,SepLLM將KV緩存使用量減少了50%以上,同時(shí)計(jì)算成本降低28%,訓(xùn)練時(shí)間縮短26%,推理速度顯著提升。這意味著SepLLM不僅能夠提高計(jì)算效率,還能降低資源消耗,為實(shí)際應(yīng)用提供了更大的靈活性。
3. 多場(chǎng)景部署靈活性
SepLLM支持從零訓(xùn)練、微調(diào)和流式應(yīng)用等多種部署場(chǎng)景,并能與預(yù)訓(xùn)練模型無縫集成。這一特性使得SepLLM在不同應(yīng)用場(chǎng)景中具有廣泛的適用性,能夠滿足各種不同的需求。
4. 支持多節(jié)點(diǎn)分布式訓(xùn)練
SepLLM的代碼庫支持高效的多節(jié)點(diǎn)分布式訓(xùn)練,并集成了多種加速訓(xùn)練的操作,如fused rope和fused layer norm。這一功能使得SepLLM在大規(guī)模訓(xùn)練場(chǎng)景中表現(xiàn)出色,能夠顯著提升訓(xùn)練效率。
SepLLM的技術(shù)原理
1. 稀疏注意力機(jī)制
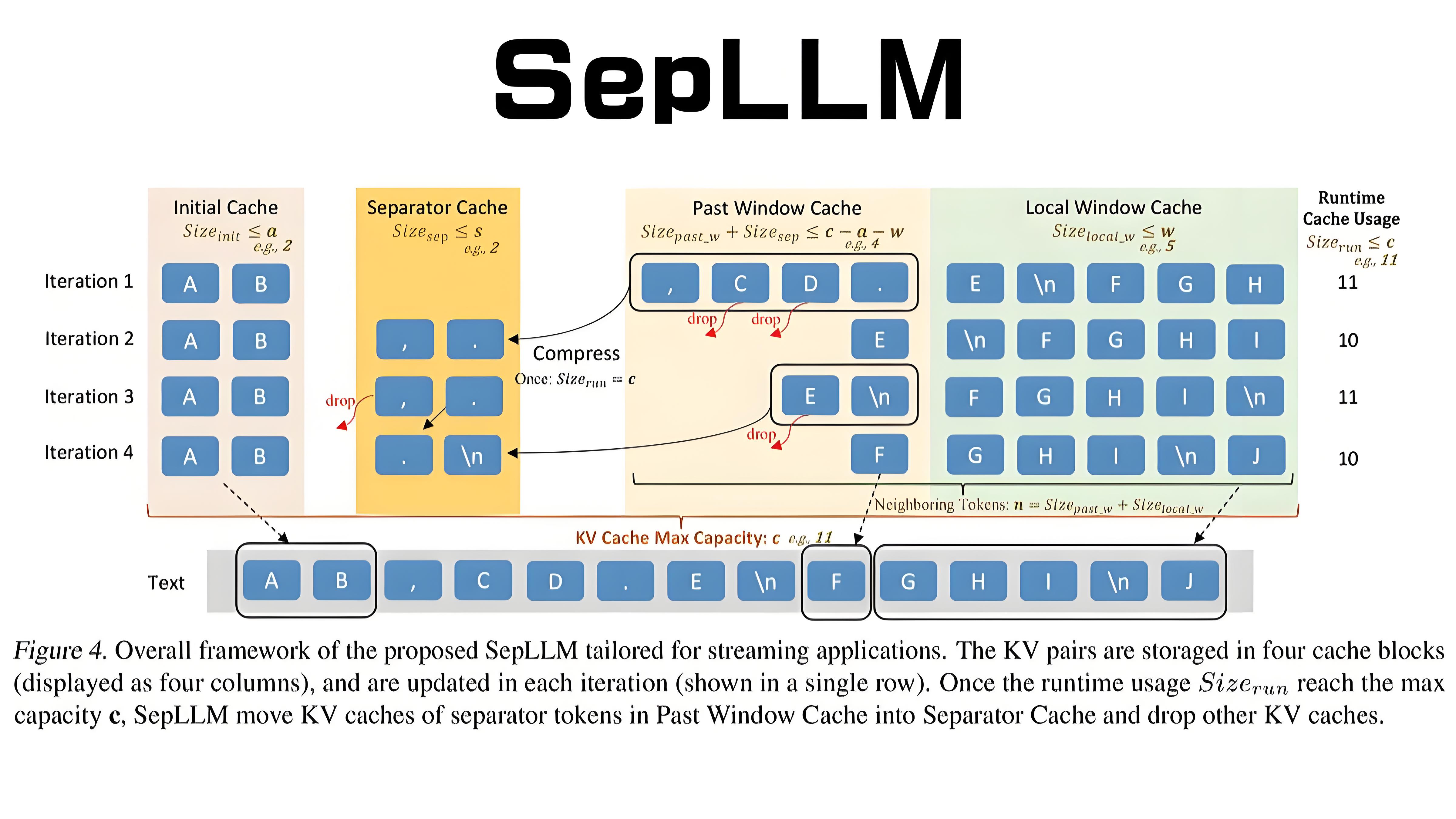
SepLLM主要關(guān)注三類標(biāo)記:初始標(biāo)記、鄰近標(biāo)記和分隔符標(biāo)記。在自注意力層中,SepLLM通過mask矩陣限制注意力計(jì)算范圍,僅計(jì)算上述三類標(biāo)記之間的注意力,從而實(shí)現(xiàn)稀疏化。這種稀疏注意力機(jī)制顯著減少了計(jì)算量,提高了計(jì)算效率。
2. 初始標(biāo)記(Initial Tokens)
初始標(biāo)記是序列開始的若干標(biāo)記,作為注意力的錨點(diǎn)。通過關(guān)注初始標(biāo)記,SepLLM能夠更好地捕捉序列的整體語義信息。
3. 鄰近標(biāo)記(Neighboring Tokens)
鄰近標(biāo)記是當(dāng)前標(biāo)記附近的標(biāo)記,用于保持局部語義連貫性。通過關(guān)注鄰近標(biāo)記,SepLLM能夠更好地捕捉局部上下文信息,從而提高模型的表達(dá)能力。
4. 分隔符標(biāo)記(Separator Tokens)
分隔符標(biāo)記如逗號(hào)、句號(hào)等,用于壓縮存儲(chǔ)段落信息。通過利用分隔符標(biāo)記,SepLLM能夠有效地壓縮段落信息,減少計(jì)算負(fù)擔(dān)。
5. 動(dòng)態(tài)KV緩存管理
SepLLM設(shè)計(jì)了專門的緩存塊,包括初始緩存、分隔符緩存、歷史窗口緩存和局部窗口緩存。通過周期性壓縮和更新策略,SepLLM能夠高效處理長(zhǎng)序列,同時(shí)減少KV緩存的使用。
SepLLM的應(yīng)用場(chǎng)景
1. 流式應(yīng)用
SepLLM適用于多輪對(duì)話、實(shí)時(shí)文本生成等流式場(chǎng)景,支持無限長(zhǎng)度輸入,保持高效的語言建模能力。這一特性使得SepLLM在實(shí)時(shí)交互場(chǎng)景中具有廣泛的應(yīng)用前景。
2. 推理與內(nèi)存優(yōu)化
通過減少KV緩存和計(jì)算成本,SepLLM適用于資源受限的環(huán)境,如邊緣計(jì)算、移動(dòng)設(shè)備等,能夠顯著降低部署成本。
3. 工業(yè)應(yīng)用
在大規(guī)模商業(yè)應(yīng)用中,SepLLM能夠降低部署成本,提升服務(wù)效率,支持高并發(fā)請(qǐng)求。這一特性使得SepLLM在工業(yè)界具有重要的應(yīng)用價(jià)值。
4. 研究與創(chuàng)新
SepLLM為注意力機(jī)制優(yōu)化提供了新的思路,支持多語言、特定領(lǐng)域優(yōu)化和硬件適配等研究方向。這一特性使得SepLLM在學(xué)術(shù)研究中具有重要的意義。
SepLLM的項(xiàng)目地址
-
項(xiàng)目官網(wǎng):https://sepllm.github.io/
-
Github倉庫:https://github.com/HKUDS/SepLLM
-
arXiv技術(shù)論文:https://arxiv.org/pdf/2412.12094
結(jié)語
SepLLM作為一種高效的框架,通過創(chuàng)新的分隔符壓縮技術(shù),顯著提升了大語言模型的推理效率和內(nèi)存使用效率。它在長(zhǎng)文本處理、推理與內(nèi)存優(yōu)化、多場(chǎng)景部署靈活性以及支持多節(jié)點(diǎn)分布式訓(xùn)練等方面具有顯著優(yōu)勢(shì)。無論是學(xué)術(shù)研究還是工業(yè)應(yīng)用,SepLLM都為大語言模型的優(yōu)化提供了全新的思路和解決方案。未來,隨著技術(shù)的不斷進(jìn)步,SepLLM有望在更多領(lǐng)域發(fā)揮重要作用,推動(dòng)人工智能技術(shù)的進(jìn)一步發(fā)展。